Linux Kernel Module for Memory and Per-Process RSS via /proc
Building a Linux Kernel Module for Memory and Per-Process RSS via /proc
User-space utilities such as top, htop, and free present a polished view of system memory usage, but they abstract away substantial kernel-level mechanics. To understand how Linux actually tracks memory—both globally and per process—I implemented a Linux kernel module that exposes system-wide memory statistics and per-process Resident Set Size (RSS) directly through /proc.
The result is a minimal, educational kernel-space alternative to user-space monitoring tools, designed explicitly to reinforce core Linux kernel concepts rather than replace existing utilities.
Overview
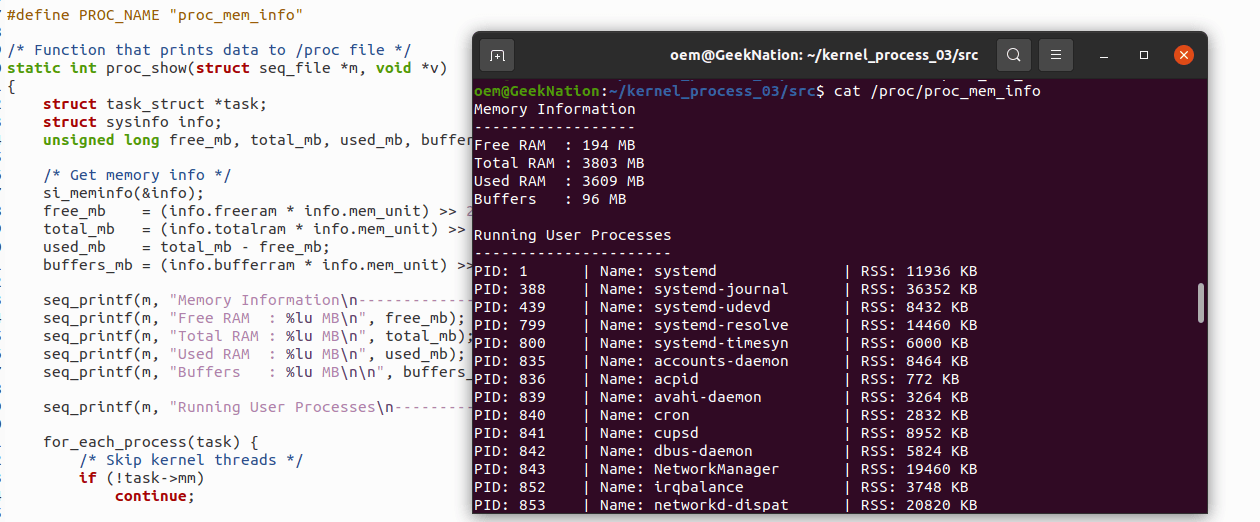
The module registers a virtual /proc entry that reports:
- System-wide memory statistics (total, free, used, buffers)
- Per-process memory usage (RSS) for all user-space processes
All data is gathered inside the kernel, without relying on /proc/meminfo or /proc/[pid]/status as intermediaries.
Module Functionality
/proc Interface
The module creates a virtual proc entry:
This file does not exist on disk. Its contents are generated dynamically each time it is read.
System-Wide Memory Statistics
The kernel’s global memory state is retrieved using si_meminfo():
- Total RAM
- Free RAM
- Used RAM
- Buffer memory
These values come directly from kernel accounting structures, ensuring accuracy and eliminating any user-space interpretation.
Per-Process RSS Reporting
To report per-process memory usage, the module:
- Iterates over all tasks using
for_each_process - Skips kernel threads (which have no user memory context)
- Extracts RSS using
get_mm_rss(task->mm)
For each eligible process, the output includes:
- PID
- Process name (
comm) - RSS in pages (or converted to kilobytes)
This mirrors how tools like top internally derive memory usage, but without leaving kernel space.
Safe and Scalable Output with seq_file
The module uses the seq_file API to emit output:
- Supports large output safely
- Automatically handles pagination
- Prevents buffer overflows
- Avoids manual offset and length tracking
This is the canonical mechanism for /proc entries that may grow beyond a single page.
Key Kernel Concepts Reinforced
Building this module clarified several core Linux internals that are often hidden by user-space abstractions.
1. Memory Accounting via mm_struct
- RSS is tracked at the
mm_structlevel - Kernel threads do not have an
mm_struct - User processes share memory mappings in predictable ways
Understanding this explains why some processes appear in ps but not in memory listings.
2. Dynamic Nature of /proc
/procfiles are generated on demand- No persistent storage exists for their contents
- Read operations invoke kernel callbacks
This reinforces that /proc is an interface—not a filesystem in the traditional sense.
3. Kernel Iteration Over Processes
for_each_processwalks the global task list- Requires care to avoid dereferencing invalid memory
- Must handle tasks exiting concurrently
Even read-only inspection requires disciplined kernel programming.
4. Why seq_file Is Mandatory for Real Modules
Manual string buffers are unsafe for variable-length output. The seq_file API:
- Manages internal buffers automatically
- Scales with process count
- Is required for production-quality
/procmodules
Debugging and Learning Challenges
Secure Boot and Kernel Lockdown
On UEFI systems with Secure Boot enabled:
- Unsigned kernel modules are rejected—even for root
- The kernel enforces lockdown mode
Resolution involved:
- Generating a Machine Owner Key (MOK)
- Signing the module using
sign-file - Enrolling the key via
mokutil
This highlighted the security model modern kernels enforce by default.
vermagic Mismatches
Several build failures were traced to:
- Compiling against incorrect kernel headers
- Header versions not matching the running kernel
This reinforced the importance of:
- Matching
uname -rexactly - Avoiding stale header packages
Kbuild and Makefile Discipline
Kernel builds exposed why:
- Kernel Makefiles must be path-sensitive
- Build logic should be minimal and kernel-centric
- Project orchestration (docs, scripts, tooling) must remain outside Kbuild
Mixing human-oriented build steps with kernel build logic leads to fragile modules.
Why This Matters
User-space tools provide convenience. Kernel modules provide truth.
By implementing this module, the following became concrete rather than theoretical:
- How Linux accounts memory internally
- How process memory differs from system memory
- Why certain abstractions exist in user-space tools
- How kernel APIs prioritize safety and scalability
This project was not about performance or production deployment—it was about understanding Linux from the inside out.
Summary
This kernel module demonstrates:
- Creating a dynamic
/procentry - Extracting global memory data using
si_meminfo - Iterating safely over processes with
for_each_process - Computing per-process RSS via
mm_struct - Using
seq_filefor robust output - Navigating Secure Boot, module signing, and Kbuild pitfalls
For anyone serious about systems programming, kernel development, or low-level performance work, projects like this provide insight that no user-space API can fully replicate.
The complete source code for this Linux kernel module is available on GitHub Repository
If needed, this can be extended further to:
- Filter processes by UID
- Export data via
debugfs - Track memory deltas over time
- Integrate with eBPF for hybrid kernel/user analysis




